 Introduction
Introduction

I've learned something about how the systems of traditional publishing work, since I started in 2012. As a career systems technologist, I've paid particular attention to the data systems, standards, and tools that I've been able to learn about.
While it's a truism that traditional authors who have gone hybrid or converted completely to independent publishing have shared a lot about traditional publishing with the indie community, by the nature of things we don't get a lot of conversations from the techies in the book trade, so it's not terribly easy coming up to speed on the technical systems used by traditional publishers.
Why do I care?
Common Problems
I can't help but notice, whenever I compare my own ebook listings at a retailer with a traditional publisher's listings, that theirs are often cleaner and more complete. Combined with the knowledge that they have large catalogues to maintain, I want to know how that's done, so that I can achieve the same effect. My own catalogue is now 24 titles, so it's not just a matter of data quality but also data quantity.
Managing and Updating Metadata for Many Titles
Whenever I have a bright idea about a better way to manage keywords or categorization, or how to adjust pricing or format book descriptions, I often find myself facing my catalogue and shaking my head about 24 titles times all my distributors.
Today my ebooks are widely distributed. I go directly to Amazon, Barnes&Noble, Kobo, and Smashwords, and I use PublishDrive and StreetLib for Apple and Google Play, and for dozens of international retailers. That's in effect 6 retailer/distributors, for each of whom I might have to update 24 titles.
It would be so much better to have a single database for all my titles and just use that to update all my trading partners, so that they could update their own trading partners or international sites, wouldn't it? My massive spreadsheet can marshal all the data, perhaps, but that just sits on my computer and doesn't communicate with anyone.
Ensuring Metadata Quality
Here's a tiny example. So-called “smart quotes” (left or right-facing single or double quotes) are not understood by all systems, depending upon things like character encoding schemes. When you create your book descriptions in a spreadsheet (with default smart quotes) and copy/paste them into a system that only understands apostrophes and straight double quotes, they often manifest as unprintable characters.
Once you discover the problem and understand the issue, you have long and short book descriptions, author bios, and other text items to clean up, across all your distributed titles. Just fixing your spreadsheet so it doesn't happen again won't fix the retailers and distributors — those all have to be updated.
Providing paragraph breaks is another painful area where the learning curve can be lengthy before you arrive at a solution that works (almost) everywhere.
Presenting Similar Marketing-Specific Metadata as Traditional Publishers
Not only do I want my book metadata to be correct, I want it to be as complete as a traditional publisher. I want my book pages at a retailer to look just as good as anyone else's book pages, so that a prospective buyer has no reason to think of my books as somehow lower in quality.
A few of the leading retailers who pioneered direct access for indies have invested in serious efforts to make that possible (Amazon, Kobo, Barnes&Noble, even Ingram & CreateSpace). But there are hundreds of potential retailers out there, and they're not in the business of special catering for indie authors.
Using the Book Trade's Own Solutions
 Traditional publishers are companies like any other in a long-established industry, and they have to share data with their trading partners. The general technical term for the standards that make this possible is EDI — Electronic Data Interchange.
Traditional publishers are companies like any other in a long-established industry, and they have to share data with their trading partners. The general technical term for the standards that make this possible is EDI — Electronic Data Interchange.
At its base, all it really means is that some version of your company's datafile can get sent to another company to facilitate business. That could include financial and manufacturing data — my order goes to your company and your invoice comes back to me.
For the book trade, we're talking about a publisher's book data — the books' files, images, and metadata. To keep this discussion simpler, I'm restricting this article just to discuss ebooks, but print and audio editions are also candidates.
A special standard has evolved for the book trade: ONIX (ONline Information eXchange).
What is ONIX?
I've spoken at length before about ONIX and I suggest you pause and read that article. I'll wait — it's a lot to digest.
If we were traditional publishers, we'd be crazy not to use ONIX to maintain and transmit our book data to our trading partners, especially since there are intermediaries who can handle some of the nuts and bolts of the data transmission as well as the sales data and invoicing with their trading partners.
On the other hand, traditional publishers have IT departments, and we don't. Also, not all of our trading partners' trading partners (retailers all over the world) are ready to handle ONIX datafiles themselves — many of them insist on spreadsheets — and we can't afford the same sorts of intermediaries that the traditional publishers can to ease that situation.
How Can Indies Manage ONIX Data?
So, even if we want to, and are prepared to learn how, can we use ONIX data, and does it help?
I'm an IT department all by myself, so I decided to make the experiment.
Here's how it works…
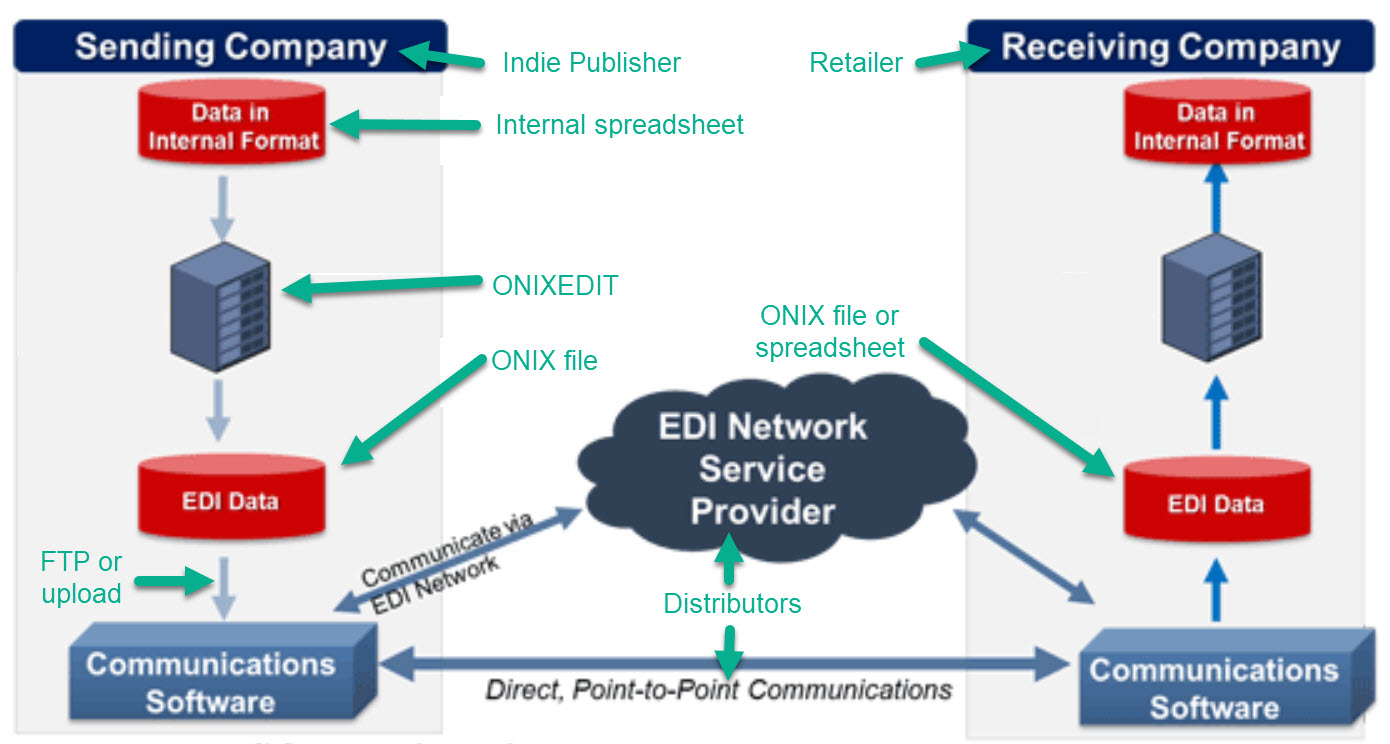
Like most of us, I have a big fat spreadsheet with all the metadata for my books. A subset of that information is useful for packaging up as an ONIX datafile.
Why a subset? For starters, my spreadsheet has identifiers for EPUB, MOBI, Print, and Audio editions. At this time, only EPUB is being handled by the distributors available to us. I also have lots of identifiers which are retailer-specific (e.g., Amazon ASIN numbers) or bibliographic rather than commercial (ISNI numbers). So not all the data in my master spreadsheet is appropriate for my ONIX file.
I picked up the ONIXEDIT software to create the ONIX XML datafile. This presents a complicated series of forms that allows me to define every single ONIX XML data element that is useful for my books. This is not for the faint-of-heart — the learning curve is substantial and it helps quite a bit if you're something of a data geek already. But it can be done, there is plenty of documentation, and the technical support folks are very responsive, especially considering their more usual customers are techies already in the book trade.
Where Can We Use ONIX Data?
Well, that's the good news. The retailers you go to directly have online forms instead, but the two most advanced and forward-thinking distributors available to us, StreetLib and PublishDrive, each accept ONIX data feeds. That was, in fact, the knowledge that spurred me on to take this step. At the time I started, I had all my books already at PublishDrive and was just about to put them all up on StreetLib.
The great thing about ONIX data is that I only need to make one master file, and both my distributors can use it. So I built my ONIX master file using ONIXEDIT, and made one output file for PublishDrive with 2 new book bundles, and a different output file for StreetLib with all my titles.
It's taken a little fine-tuning from responsive tech support at the distributors and corrections and adjustments from me in building the ONIX records. Even ONIXEDIT got involved, since there were parts of the ONIX 3.0 standard they hadn't implemented yet.
And it worked!
I almost wish there were some sort of universal change I had to make to all my titles right now, just to revel in a push-button update. I will certainly be going this route with my next releases — a permanent change in my processes.
The Current State of the Art
What about the distributors themselves? So far, there are only so many of their publishing customers (indie or trad) who are taking advantage of the ONIX possibility, but some of those have large catalogues of titles. This can only grow for them as more take advantage of the functionality on offer.
There are some less fundamental ONIX marketing data elements, not yet supported by the distributors, that we would find compelling (e.g., editorial reviews), which I hope to see added to the input specifications as soon as possible. My wants are simple — all I want is everything the traditional publishers can pass to their trading partners.
More distributors like PublishDrive and StreetLib might arise, but those two distributors have set the bar high enough that I would expect to see ONIX input feeds as part of their functionality, too, especially as they hope to attract publishers as well as indies.
The ONIX feeds were (and are) an investment for the distributors in becoming and staying competitive, just like they're an investment for me, and I hope they deepen that investment.
Conclusion
I anticipated this would take some real effort to get past the learning curve, and even at that I underestimated it, but I'm past that now. I learned a lot about the uses of the individual data elements that was an education in itself about the commercial data that the book trade uses. In passing, the Bowker ISBN records hold few mysteries for me anymore — those are all part of the ONIX data set, and if you're large enough (I'm not), you can send ONIX feeds to Bowker, too, and control the whole publication/release cycle that way. It also means you can use ONIX documentation to understand exactly what the Bowker data fields are trying to collect, and get smarter about the book trade requirements.
I now have functioning ONIX feeds to my two big distributors, and that makes me very happy.
But is this a bridge too far? Maybe not for small publishers, but probably so for most indies…
A service provider could arise who finds a way to take ordinary per-title data from a form or spreadsheet and creates ONIX records, for a fee. So instead of investing in ONIXEDIT and learning how to create the ONIX records, an indie could fill out a very full form, get back an ONIX file, and use it for both distributors. On the other hand, an indie today can just fill out the standard form at both distributors and skip an intermediary, so I can't see that happening at this point.
I look at it as an investment in the future, partly to ease the effort of maintaining more and more titles in my catalogue, and partly as a way of providing all the data the traditional publishers do, once the distributors catch up.
Willing to invest in the learning curve yourself?
Way out of my league, Karen.
Are you in a place where you might offer the service? Considering that you have to do all this for your own books – and weighing whether the income would be worth your time and efforts.
Me, one book, Amazon. I used to have the brain that might have attempted this, but it barely has enough neurons firing any more to write with.
But it’s fascinating to see how deep you’ve gone into the processes and data. Hope it gives your books the extra boost.
I don’t think the service would be cost effective at this point, Alicia. An indie today could fill out a form twice (for each distributor) or once (for a service provider) — not a very compelling service offering.
As more distributors become available, or more direct retailers offer ONIX, that evaluation might change.
This is fascinating. But i just looked up your listing on Blio (On a Crooked Track) and it doesn’t look like the changes have gone into effect yet. Do you have an idea of how long it’s going to take? Or do some retailers accept the changes, while others keep their original data?
Sorry for the delay in responding, Dale…
I get to Blio via Smashwords (not PublishDrive or StreetLib), who does not accept ONIX records. At this point, I only use Smashwords for its retail site, and for the (very few) channels it has which are not available via SL and/or PD.
In principle, I can send ONIX records to Amazon, but I would probably have to define myself differently to them, and I see no urgency to explore that.
You do raise a different question — how to check up on how the data is conveyed to your distributors’ partners. You need to audit that every few months. https://hollowlands.com/2017/03/checking-up-on-book-distributors/
[…] stored in systems and is batch-managed. Methods of batch-management can be an Excel sheet or an Onix provider, for example). But for small and indie authors, batch management is not very important. However, entering […]
I really appreciate the time you took to write and share this information. Onix is a serious commitment, obviously. I look forward to following your Onix adventures and hope there is a very satisfactory ROI for you.
My pleasure. I always think it’s such a pain-in-the-neck for me to figure out how some of these things work (lots of pioneering goes on as an indie) that it behooves me to spell it out for other people, to the degree that I understand it.
Hello,
Thanks for the info. I’m trying to get things going with a central system like ONIXedit, but finding many, many roadblocks. (I have 100 active ISBNs)
Books in Print or Bowker’s BookWire.com after much misinformation, finally said that small publishers could only update their data via their online system – one data point at a time – then i found out that we can send them ONIX files, but only after a $2500 fee!! They sent me a link from Feb 20, 2014 https://support.proquest.com/articledetail?id=kA0400000004JNGCA2 … Any thoughts on the EDI aspect to this?
I am also concerned with updates. For instance, i update details on Amazon (to look good on their site), then an update comes from Lightning Source and screws that up. Trying to avoid such a clusterF…
You have hit the reason why indies can’t send ONIX records to Bowker — wrong cost structure for us — just like the reason that Firebrand (https://hollowlands.com/2017/03/book-metadata-onix-digital-asset-management-dam-systems/) can’t yet be used as a service by us, though they’re very friendly. We are not at the right scale to just plug into the existing systems (even if we can find out what those are), and most of the existing players don’t think it necessary or cost effective to create a different level of access for indies (Ingram being a notable exception).
Though we meet ex-trad authors with some frequency, we don’t meet the back-office techies from the book trade, and so we have only a dim understanding of what is possible for the people in the trade. And the book trade is not in general welcoming to newbies of any kind. (https://hollowlands.com/2017/01/participating-in-the-book-trade/).
I consider it a “win” just to understand that the Bowker ISBN record fields are basically ONIX fields –it lets me look up the official descriptions for those fields from the BISG reference guides.
If I had enough titles (still under 30, though the ISBNs are over 70), I would have to start comparing my metadata volatility (the utility of using ONIX) with the profitability of going to individual retailers directly, and consider using PublishDrive (or Streetlib) to take on my direct retailers, too, at a royalty cost, just to consolidate it. I’m not there yet (or perhaps ever).
In terms of match-up for ebook to print, updating Amazon metadata to override imported metadata (e.g., Ingram) is probably not wise. Amazon (and some of the others, like Kobo) make some effort to be extra-helpful to indies, but you always want to update all the metadata at the furthest upstream source, unless it’s absolutely unavoidable. Personally, I try to make Amazon and B&N correctly match the editions together, but try to avoid any metadata changes for print editions on those sites, even where it’s allowed.
It’s hard enough keeping your exported metadata clean on less sophisticated retailer sites. (https://hollowlands.com/2017/03/checking-up-on-book-distributors/)
Wonderful! Thanks for sharing all your research.
Hey! Thanks for this. It’s been three years since you posted. Could you give an update on using ONIX as an indie publisher?
Thanks,
Darcy
I’m an old data techie/computer pro, and I believe in subscribing to the standard metadata standards in use in an industry. Thus I was chuffed when I discovered that I could play in the same pool as the big boys by using ONIX.
So far, I have kept my annual subscription but…
BENEFITS
Other than forcing me to make my metadata even tidier than it was, I can’t detect ANY changes to uptake (purchases) just because I’m in all the systems that ONIX facilitates. The temptation to continue expanding discoverability (because you can) does not trump marketing. Doesn’t matter if my books are everywhere if no one knows about them. And it doesn’t matter if I accurately classify SERIES and NUM-IN-SERIES and SUBJECT, etc., using all the correct tools and appropriate classification terms if the presenting online retailer website makes no allowance for such things.
I had hoped that I could at least use the ONIX output for my data feeds into PublishDrive and StreetLib, to simplify at least a bit of my distribution, but (alas) PublishDrive seems to have decided (permanently?) that there are few other indies as crazy as me, so they don’t integrate with it (last I checked). StreetLib, on the other hand, raised my hopes by having an ONIX based import, but then dashed them by woefully inadequate tech support. I lost a year due to (recovered from) medical issues, so I haven’t gone back around to see what the current state of affairs is re: ONIX integration, but I’m not optimistic.
COST
The only out-of-pocket cost is the annual fee. I can’t justify it vs increase in earnings, but I (so far) still feel obligated to give it a chance, as an investment in the maturation of the industry. However, realistically I do not expect ANY innovations from the book publishing industry to actually justify my hope.
TECHNICAL LEARNING CURVE
This is the big issue… The folks at ONIXEdit are very friendly and willing to help, and they have a lot of documentation, but you will surely underestimate the size of the learning curve unless you’re a data techie, and probably even then (I did).
On the other hand… I like this sort of intellectual challenge and spent far more time than I can possibly justify getting into all the metadata and what the correct values should be. I found it very, very educational about the innards of how books are classified and stored in the industry, as I’ve mentioned in my various articles dealing with ONIX on the Hollowlands site (search: https://hollowlands.com/?s=ONIX). But you will need database background skills (conceptually) to get started, and it’s a serious time sink. It’s all lists of appropriate data descriptors and proper fill-ins.
If anyone reading this is not fatally intimidated by this, I’d be glad to show you excerpts and samples of how my (still accurate) ONIX database sets up, which would help you with your equivalent (or even just to get a sense of what it’s like).